KI und der Schweizer Arbeitsmarkt:
Erste Evidenz zu Auswirkungen auf Arbeitslosigkeit und Stellenausschreibungen
Jeremias Klaeui1,2 und Michael Siegenthaler1
1KOF Institut, ETH Zürich
2CREST, Paris
Diese Studie ist Teil des Projekts «Labor Market Inequality in Modern Labor Markets», das vom Schweizerischen Nationalfonds unterstützt wird (Projektnummer 100018-232103)
Zusammenfassung
In diesem Bericht untersuchen wir die frühen Auswirkungen von KI- Sprachmodellen (Large Language Models, LLMs) auf den Schweizer Arbeitsmarkt. Wir analysieren, ob Berufe mit hoher KI-Betroffenheit vor und nach der Einführung von ChatGPT und anderen LLMs im Herbst 2022 andere Trends bei Arbeitslosigkeit und Stellenausschreibungen zeigen als Berufe mit niedriger Betroffenheit. Es zeigt sich: Nach der Einführung generativer KI entwickelte sich die Arbeitsmarktsituation in Berufen mit hoher KI-Betroffenheit deutlich weniger erfreulich als in Berufen mit geringer Betroffenheit. Dies spricht für negative Arbeitsnachfrageeffekte generativer KI in exponierten Berufen. So stieg die Zahl der registrierten Stellensuchenden gemäss den Registerdaten der Arbeitslosenversicherung in stark exponierten Berufen um bis zu 27 % stärker als in weniger exponierten Berufen. In umfassenden Stelleninseratsdaten eines privaten Datenanbieters zeigt sich ein relativ stärkerer Rückgang der Zahl der Stellenausschreibungen. Analysen mit einem zweiten Mass für KI-Betroffenheit liefern qualitativ ähnliche Ergebnisse mit etwas kleineren Effektgrössen.
Vorgehen und Einordnung
Die Analyse stützt sich auf monatliche Arbeitslosenzahlen des SECO nach Beruf (gemäss der Berufsnomenklatur ISCO-19, 4-Steller) und Altersgruppe sowie auf Berufsebene aggregierte Mikrodaten von Stelleninseraten des auf Arbeitsmarktdaten spezialisierten, privaten Anbieters x28 AG. Beide Datensätze sind umfassend: Die Arbeitslosenregisterdaten des SECO erfassen das Universum aller Stellensuchenden, die auf Schweizer Arbeitsämtern als stellensuchend oder arbeitslos registriert sind. Die x28-Daten erfassen nahezu das Universum aller Online-Stelleninserate im Schweizer Arbeitsmarkt. Der Beobachtungszeitraum erstreckt sich von September 2016 bis August 2025 für die Inseratedaten, und von September 2010 bis August 2025 für die Arbeitslosenregisterdaten. Für deskriptive Analysen verwenden wir monatliche Zeitreihen, für die Event-Studies bilden wir Jahresfenster von September bis August. Zwar böte sich aufgrund der Einführung von ChatGPT im November 2022 ein Jahresfenster von November bis Oktober an. Wir entschieden uns jedoch für ein Jahresfenster von September bis August, damit auch ins letzte Jahresfenster ein gesamtes Datenjahr einfliesst.
Methodisch orientieren wir uns an Brynjolfsson, Chandar und Chen (2025), die vergleichbare Analysen für die USA durchführen. Zur Messung der KI-Betroffenheit nutzen wir in erster Linie das Expositionsmass von Eloundou et al. (2024). Dieses Mass basiert auf der Zerlegung von Berufen in einzelne Aufgaben (Tasks) und klassifiziert, in welchem Ausmass LLMs die Erledigungszeit dieser Tasks um mindestens 50 Prozent reduzieren können. Die einzelnen Klassifikationen werden zu einem Index auf Berufsebene (β-Mass) aggregiert. Stark betroffen sind demnach Berufe, in denen LLMs zu grossen Zeitgewinnen in vielen der Tätigkeiten führen, die im Beruf relevant sind. Im Rahmen unserer Analysen haben wir dieses Betroffenheitsmass erstmals für die ISCO-Berufsnomenklatur berechnet, die in der Schweiz typischerweise zur Unterscheidung von Berufen verwendet wird. Weitere Einzelheiten zum Expositionsmass sowie eine Übersicht der Top-10- und Bottom-10-Berufe finden sich im Abschnitt „Technische Details" weiter unten.
Gemäss dem Mass von Eloundou et al. (2024) zählen Kodierer und Korrekturleser*innen (β = 0.96), Anwendungsprogrammierer*innen (β = 0.94) sowie Datenbankentwickler*innen und -administrator*innen (β = 0.91) zu den am stärksten KI-exponierten Berufen. Eine geringe Betroffenheit weisen dagegen Berufe wie das Reinigungspersonal (β ≈ 0.00), Hauswarte (β = 0.00) oder Näher*innen (β = 0.00) auf. Auffällig ist, dass besonders viele Wissensberufe mit erhöhten Qualifikationsanforderungen und überdurchschnittlichen Löhnen exponiert sind gegenüber KI. Dies ist ein wesentlicher Unterschied zur bisherigen Digitalisierung (beispielsweise durch Computer und Roboter), von der in erster Linie Berufe mit einem hohen Anteil an Routinetätigkeiten betroffen waren. Diese befinden sich eher am unteren oder mittleren Ende der Einkommensverteilung und weisen geringe bis mittlere Qualifikationsanforderungen auf. Dies zeigt auch, dass KI-Sprachmodelle die Grenze, was Computer tun können, in den letzten Jahren deutlich verschoben und damit viele Tätigkeiten neu der Automatisierung ausgesetzt sind.
In die Analyse fliesst zudem ein zweites KI-Betroffenheitsmass von Handa et al. (2025) ein. Dieses erfasst, für welche Aufgaben generative KI von den Nutzenden effektiv eingesetzt wird. Hierzu analysieren die Autorinnen und Autoren mehrere Millionen anonymisierte Interaktionen mit dem Sprachmodell Claude.ai und ordnen jede Anfrage einem spezifischen Task zu. Auf dieser Grundlage lässt sich bestimmen, für wie viele Tasks eines Berufs tatsächlich KI eingesetzt wird. Handa et al. (2025) klassifizieren die Task-Anfragen zudem in fünf Kategorien, wie z.B. vollständige Aufgabenübergabe ("Übersetze dieses Dokument von HTML in Markdown"), kollaborative Prozesse ("Lass uns eine Marketingstrategie für unser neues Produkt entwerfen. … können wir konkrete Metriken ergänzen"), oder Wissenserwerb. Wir nutzen diese Kategorien zur Analyse heterogener Effekte nach verschiedenen Arten der LLM-Nutzung.
Bei der Interpretation der Ergebnisse ist es wichtig zu berücksichtigen, dass wir relative Verschiebungen zwischen Berufsgruppen betrachten, die unterschiedlich stark von KI betroffen sind. Damit isoliert die Analyse in erster Linie die direkten Substitutionseffekte der Technologie in stark von KI betroffenen Berufen – sie fokussiert sich also auf die potenziellen Verlierer der KI-Adoption in der Wirtschaft. Eine relative Betrachtung lässt jedoch keine Quantifizierung des Effekts generativer KI auf die Gesamtbeschäftigung zu. Denn Effekte generativer KI, von denen alle Berufsgruppen betroffen sind, werden in einer relativen Betrachtung ausgeblendet. Im Extremfall können Stelleneinsparungen in stark exponierten Berufen zu Stellenzuwächsen im gleichen Ausmas in wenig exponierten Berufen führen. In diesem Fall käme es zu relativen Verschiebungen zwischen den Berufsgruppen, obwohl die Gesamtzahl der Beschäftigten unverändert bliebe.
Damit bleibt insbesondere unberücksichtigt, dass KI Firmen produktiver machen kann, da sie es ermöglicht, bestimmte Aufgaben schneller zu erledigen. Solche Produktivitätsgewinne können innerhalb der Unternehmen zu einer erhöhten Nachfrage nach verschiedenen, insbesondere komplementären Berufen führen und Stellenprofile verändern (Augmentation). Darüber hinaus können Unternehmen die Produktivitätsfortschritte nutzen, um zu investieren und Arbeitsprozesse zu optimieren. Das kann die Arbeitsnachfrage eines Unternehmens ebenfalls erhöhen und sogar gänzlich neue Tätigkeiten und Berufe hervorbringen. Schlieslich können Unternehmen die Produktivitätsgewinne für Preissenkungen nutzen, von denen die Konsumentinnen und Konsumenten im Land profitieren. Die resultierenden Einkommensgewinne auf der Konsumseite können die gesamtwirtschaftliche Arbeitsnachfrage erhöhen – also selbst in jenen Bereichen ankurbeln, in denen KI gar nicht zum Einsatz kommt. Solche gesamtwirtschaftlichen Effekte werden in diesem Bericht ausgeblendet. Tatsächlich beziehen sich die Analysen auf einen Zeitraum mit wachsender Gesamtbeschäftigung in der Schweiz. Zwischen Q3 2020 und Q2 2025 ist die Zahl der Beschäftigten in der Schweiz insgesamt um 7,4 Prozent gestiegen. Möglicherweise trug der Einsatz von generativer KI bereits zu diesem Wachstum bei.
Deskriptive Ergebnisse
Die folgenden Abbildungen zeigen die zeitlichen Entwicklungen der Arbeitslosigkeit – konkret die Zahl der registrierten Stellensuchenden, von denen rund vier Fünftel auch arbeitslos sind – und die Anzahl der Stellenausschreibungen vor und nach der Einführung groser Sprachmodelle. Dabei vergleichen wir Berufe mit hoher und niedriger KI-Betroffenheit, um mögliche Unterschiede in den Trends sichtbar zu machen. Zur Vergleichbarkeit wurden alle Reihen auf Oktober 2022 mit einem Ausgangswert von 100 indexiert. Die vertikale Linie in den Grafiken kennzeichnet den Monat der ChatGPT-Einführung im November 2022.
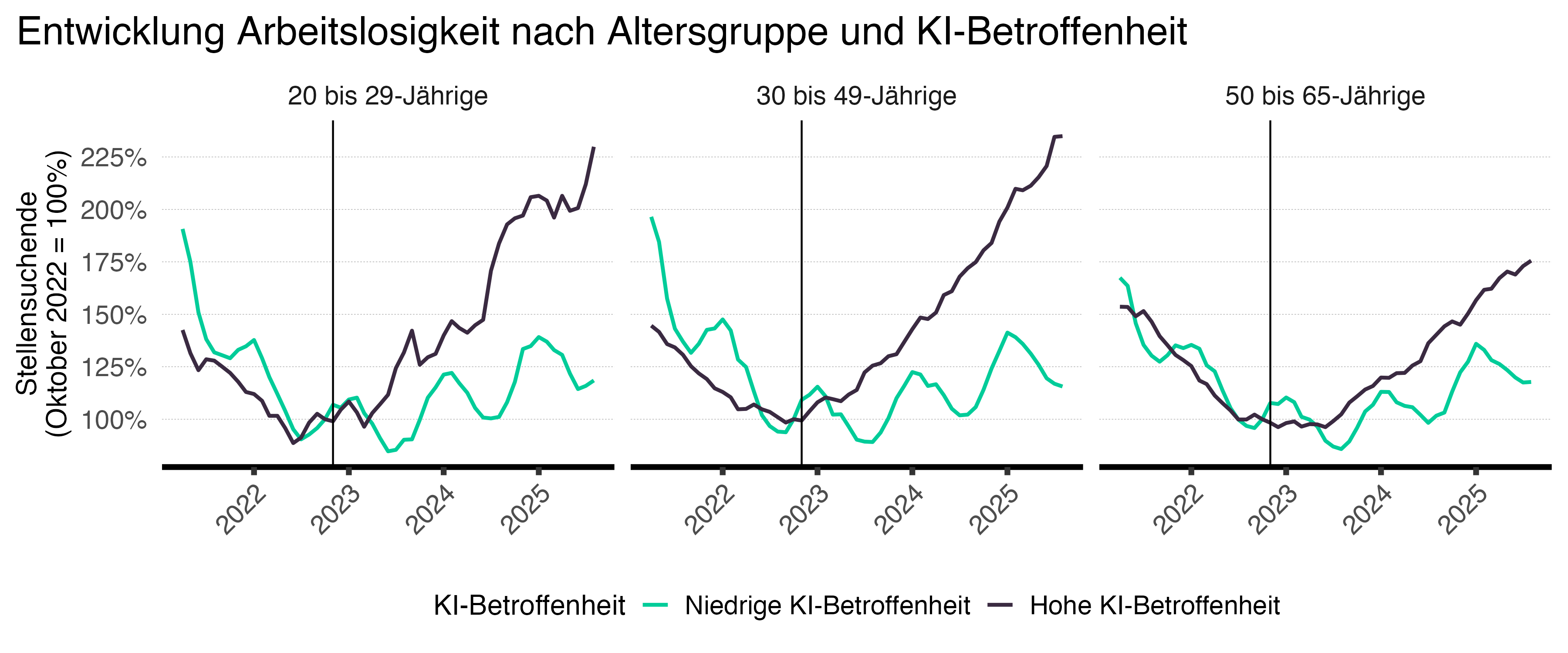
Anmerkung: Die Abbildung zeigt indexierte, monatliche Stellensuchendenzahlen für die Top-10- und Bottom-10-Berufe nach KI-Betroffenheit. Indexierung relativ zu Oktober 2022. Vertikale Linie: November 2022 (Einführung von ChatGPT). Datenquelle: SECO, Eloundou et al. (2025), eigene Berechnungen.
Seit der Einführung von ChatGPT ist die Zahl der registrierten Stellensuchenden in Berufen mit hoher KI-Betroffenheit deutlich stärker angestiegen als in Berufen mit niedriger Betroffenheit. In Berufsfeldern mit geringer KI-Betroffenheit ist zwar ebenfalls ein leichter Anstieg der Stellensuchenden zu verzeichnen, dieser ist jedoch deutlich geringer als bei stark exponierten Berufen. Zudem zeigen sich Unterschiede nach Altersgruppe: Der Anstieg der Stellensuchenden in stark KI-exponierten Berufen ist besonders ausgeprägt bei jüngeren Arbeitnehmenden, während Beschäftigte über 50 Jahren weniger stark betroffen sind, jedoch ebenfalls einen Anstieg verzeichnen. Die Zunahme der Stellensuchenden ist quantitativ bedeutsam: Bei den unter 50-Jährigen hat sich die Zahl der registrierten Stellensuchenden in stark exponierten Berufen seit Herbst 2022 mehr als verdoppelt.
Um die beobachteten Unterschiede bei der Arbeitslosigkeit besser einzuordnen, lohnt sich ein Blick auf die Nachfrageseite des Arbeitsmarktes. Stellenausschreibungen geben Aufschluss darüber, in welchem Ausmas Unternehmen neue Arbeitskräfte suchen. Die Entwicklung von Stelleninseratedaten ermöglicht auch zu unterscheiden, ob der Anstieg der Arbeitslosigkeit in KI-exponierten Berufen auf ein besonders stark steigendes Arbeitsangebot in diesen Berufen oder auf einen Rückgang der Stellennachfrage zurückzuführen ist. Die folgende Abbildung zeigt die Entwicklung der Zahl der Online-Stelleninserate in Berufen mit unterschiedlicher KI-Betroffenheit nach der Einführung groser Sprachmodelle.
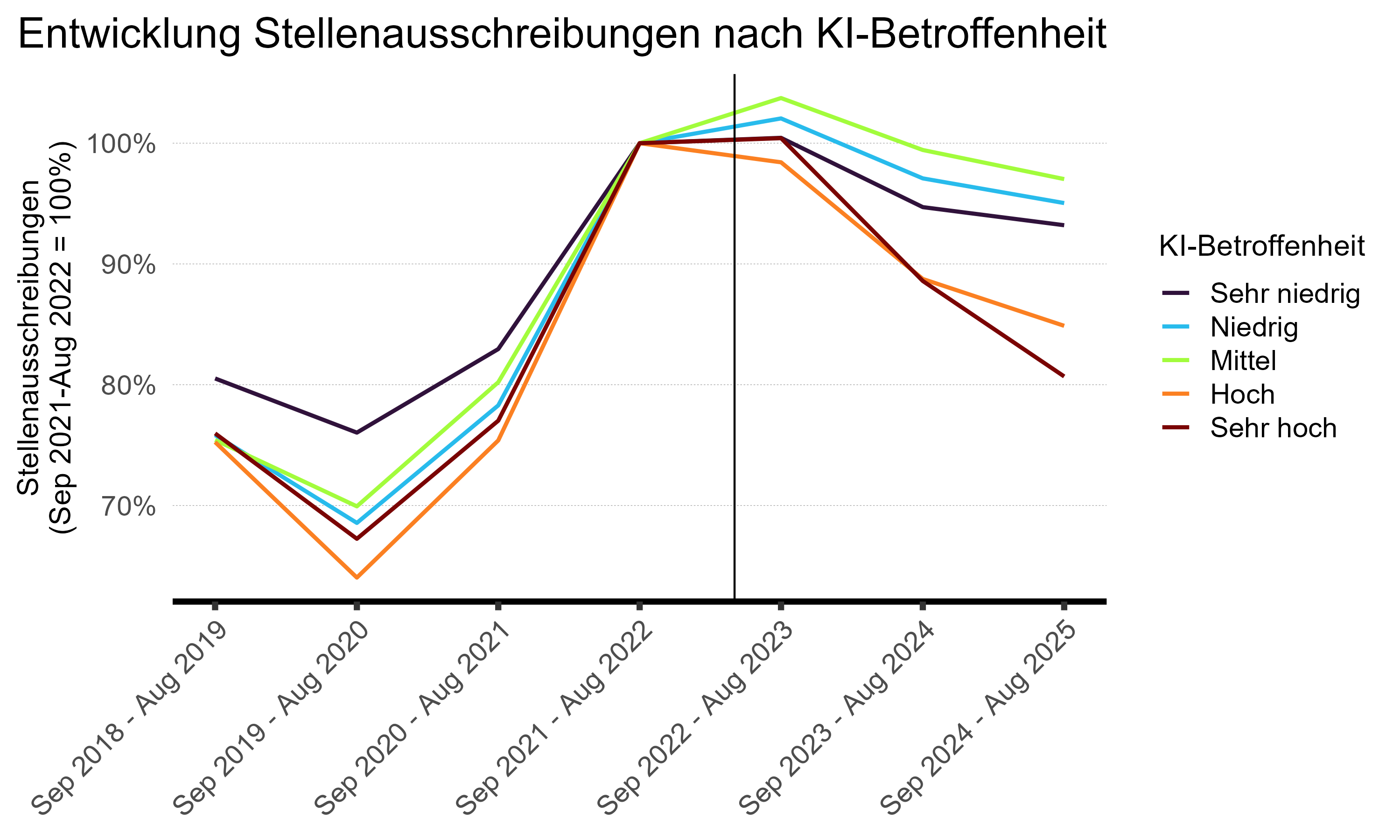
Anmerkung: Jährlich aggregierte Daten der Zahl der Stelleninserate nach Quintilen der KI-Betroffenheit. Indexierung relativ zu Oktober 2022. Vertikale Linie: November 2022 (Einführung von ChatGPT). Datenquelle: x28 AG, Eloundou et al. (2025), eigene Berechnungen.
Das Bild der Stellenmarktdaten ist mit den Arbeitslosendaten konsistent und deutet auf einen Rückgang der Arbeitsnachfrage hin. Nach der Einführung von ChatGPT und anderen LLMs geht die Zahl der Stellenausschreibungen in Berufen mit hoher und sehr hoher KI-Betroffenheit deutlich zurück, während sie in Berufen mit niedriger und mittlerer Betroffenheit nur leicht sinkt. Bis 2024/2025 erreichen die Ausschreibungen in stark betroffenen Berufsfeldern nur noch 60 bis 70 Prozent ihres Ausgangswerts vor der Einführung der LLMs. Diese Trends auf dem Stellenmarkt könnten auch die zuvor beobachteten Altersunterschiede erklären. Von einem Rückgang der Stellen sind jüngere Arbeitskräfte besonders betroffen, da sie eine grösere Wahrscheinlichkeit haben, aktiv auf Stellensuche zu sein. Ältere Arbeitskräfte befinden sich dagegen häufiger in stabilen Beschäftigungsverhältnissen und sind erst dann vom Stellenrückgang betroffen, wenn sie ihre Stelle verlieren.
Regressionsanalysen
Im nächsten Schritt werden die zuvor beobachteten Unterschiede mithilfe von Regressionsanalysen quantifiziert. Mithilfe dieser Schätzungen können wir relative Effekte zwischen Berufsgruppen beziffern und die statistische Unsicherheit beurteilen. Dazu verwenden wir eine Event-Study-Spezifikation in Form eines dynamischen Difference-in-Differences-Designs, das Veränderungen zwischen Gruppen mit unterschiedlichem Grad der KI-Betroffenheit vor und nach Einführung der LLMs quantifiziert. Die Berufe werden nach ihrem Grad der KI-Betroffenheit in Terzile eingeteilt. Dabei verwenden wir Arbeitslosengewichte: Das Terzil der am stärksten betroffenen Berufe repräsentiert somit gleichzeitig ein Drittel aller registrierten Stellensuchenden im Herbst 2022. Die Analysen vergleichen das zweite Terzil (mittlere Betroffenheit) und das dritte Terzil (hohe Betroffenheit) mit dem ersten Terzil (niedrige Betroffenheit). Da die Analyse auf Unterschiede in der Entwicklung zwischen den Berufsgruppen fokussiert ist, werden allgemeine Entwicklungen, die alle Berufe in gleichem Ausmass betreffen, herausgerechnet. Dies ermöglicht es, den möglichen Einflusses von KI besser vom Rückgang der Arbeitsnachfrage bzw. dem Anstieg der Arbeitslosigkeit zu unterscheiden, der ab Ende 2022 aufgrund der Normalisierung des Arbeitsmarktes aus konjunkturellen Gründen zu erwarten war.
Event-Study: Arbeitslosigkeit
Die Ergebnisse zeigen, dass sich die Zahl der registrierten Stellensuchenden in Berufen mit hoher KI-Betroffenheit nach der Einführung von ChatGPT und anderen KI-Modellen im Herbst 2022 statistisch signifikant stärker erhöht hat als in Berufen mit geringer KI-Betroffenheit. Der geschätzte Effekt, das heisst der geschätzte Regressionskoeffizient am Ende des Beobachtungszeitraums in der Periode September 2024/August 2025, beträgt bei jüngeren Stellensuchenden rund 27 Prozent. Bei Stellensuchenden ab 50 Jahren ist der geschätzte Effekt etwas geringer. Damit bestätigen sich die in den deskriptiven Analysen beobachteten Altersmuster auch in den modellbasierten Schätzungen. Die Regressionen zeigen zudem, dass Berufe mit mittlerer KI-Betroffenheit nach 2022 einen etwas stärkeren Anstieg der Stellensuchenden verzeichneten als Berufe mit geringer Betroffenheit. Wie zu erwarten ist, sind die geschätzten Effekte deutlich kleiner als bei stark exponierten Berufen. Für die Analyse ist auch wichtig, dass sich die Stellensuchendenzahlen in stark und weniger stark KI-betroffenen Berufen von 2016 bis 2022 ähnlich veränderten. Wie wir in den technischen Details zeigen, hatten die Berufsgruppen sogar über einen Zeitraum von zwölf Jahren vor 2022 ähnliche Arbeitslosentrends.
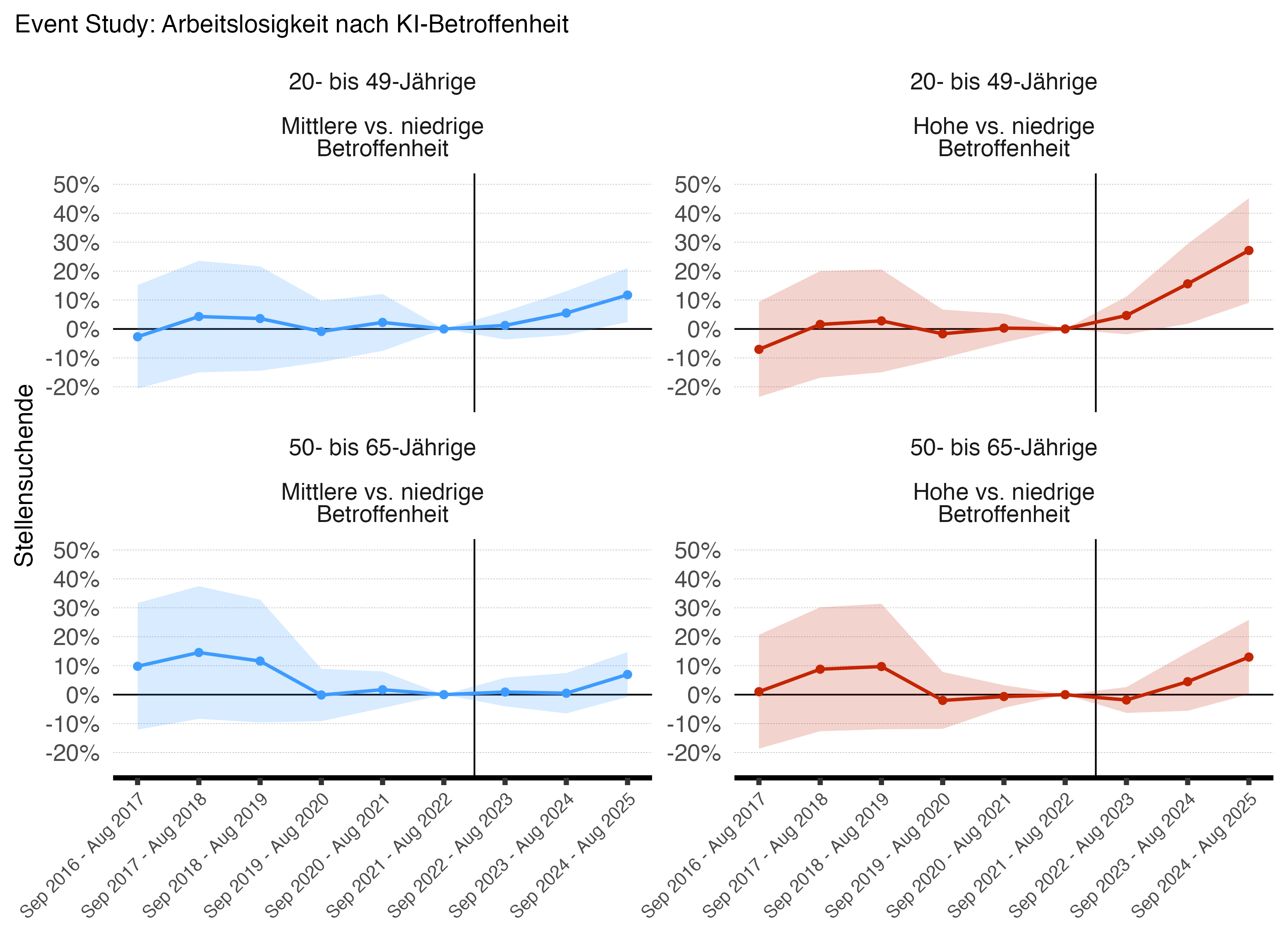
Anmerkung: Ergebnisse einer Poisson-Event-Study-Regression mit 95%-Konfidenzintervallen. Für Details siehe "Technische Details". Das erste Terzil (niedrige Betroffenheit) dient als Referenz. Marginale Effekte werden als Prozentdifferenzen zur Referenzgruppe angegeben. Die Referenzperiode ist auf null normalisiert. Die vertikale Linie markiert den Zeitpunkt kurz vor der Einführung von ChatGPT und anderen grossen Sprachmodellen im Herbst 2022. Clustering der Standardfehler auf ISCO-4-Steller Ebene. Interpretation: Positive Werte zeigen eine stärkere Zunahme der Zahl der Stellensuchenden in stark KI-exponierten Berufen relativ zum Drittel der am wenigsten KI-betroffenen Berufe.
Event-Study: Stellenausschreibungen
Auch die Stellenmarktdaten von x28 zeigen auf Basis der Event-Study-Schätzungen, dass Berufe mit unterschiedlicher KI-Betroffenheit nach der Einführung von ChatGPT und anderen KI-Modellen auseinanderklaffen. Vor 2022 entwickelten sich die Zahl der Stelleninserate in beiden Berufsgruppen – mit Ausnahme des Jahres 2020 – ähnlich. Danach werden die Regressionskoeffizienten, die den Effekt in stark KI-exponierten Berufen erfassen, negativ. Unmittelbar nach Herbst 2022 sind die Effekte moderat, verstärken sich in den Folgejahren jedoch. Am Ende des Beobachtungszeitraums liegen die marginalen Effekte bei −38 % relativ zu den wenig betroffenen Berufen. Allerdings ist die Größenordnung dieses Effekts mit einer gewissen Vorsicht zu interpretieren. Denn bereits im Jahr 2020, dem ersten Jahr der Pandemie, entwickelte sich der Stellenmarkt in stark KI-exponierten Berufen signifikant schwächer als in weniger exponierten Berufen. Zwar war der Unterschied kleiner und weniger persistent als nach der Einführung von LLMs. Dennoch deutet der signifikant negative Schätzer im Jahr 2020 darauf hin, dass auch andere Faktoren die relative Entwicklung des Stellenmarkts in den Berufsgruppen beeinflussen.
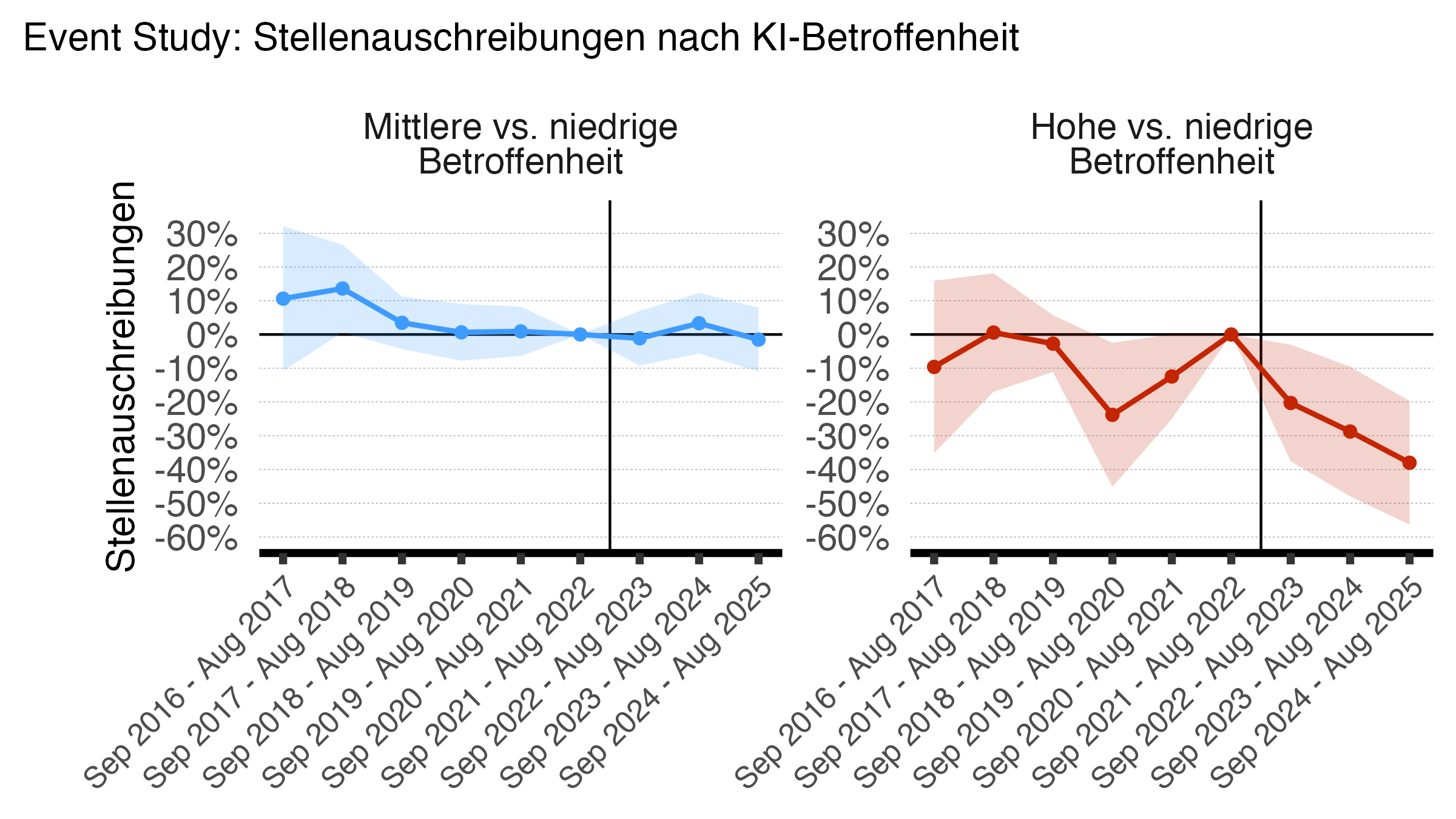
Anmerkung: Ergebnisse einer Poisson-Event-Study-Regression mit 95%-Konfidenzintervallen. Für Details siehe "Technische Details". Marginale Effekte werden als Prozentdifferenzen relativ zum ersten Terzil angegeben. Die vertikale Linie markiert den Zeitpunkt kurz vor der Einführung von ChatGPT und anderen grossen Sprachmodellen im Herbst 2022. Clustering der Standardfehler auf Unternehmensebene. Interpretation: Negative Werte zeigen einen stärkeren Rückgang der Stellenausschreibungen in stark KI-exponierten Berufen relativ zu dem Drittel der am wenigsten betroffenen Berufe.
Beispiele: Effekte in einzelnen Berufen mit hoher KI-Betroffenheit
Eine zentrale Frage ist, welche konkreten Berufe innerhalb des Terzils der am stärksten exponierten Berufe besonders zum Anstieg der Arbeitslosigkeit beigetragen haben. Die folgende Grafik zeigt den Verlauf der 30 Berufe mit der höchsten KI-Betroffenheit im Vergleich zu dem Terzil der am wenigsten exponierten Berufe. Nach der Einführung großer Sprachmodelle steigt die Arbeitslosigkeit in den meisten dieser Berufe stärker an als in der Vergleichsgruppe mit niedriger KI-Betroffenheit. Besonders ausgeprägt ist der Anstieg bei Anwendungsprogrammierer:innen, Softwareentwickler:innen und Systemanalytiker:innen. Hier erhöhte sich die Arbeitslosigkeit fast doppelt so stark wie in wenig exponierten Berufen. Das gilt insbesondere für jüngere Arbeitskräfte, wie Zusatzauswertungen zeigen. Die Ergebnisse in diesen IT-Berufen deuten zudem darauf hin, dass die Neueinstellungen von Softwareentwicklern und -ingenieuren, die Unternehmen bei der Einführung von KI unterstützen, bislang nicht ausreichen, um den Rückgang der Stellennachfrage in diesem Bereich auszugleichen. Auch bei Arbeits- und Personalvermittler:innen, Journalist:innen und im Marketing sind markante relative Zuwächse zu verzeichnen. In Berufen mit stärker administrativem oder unterstützendem Charakter – etwa allgemeine Bürokräfte oder Vertriebsagent:innen – sind die Differenzen schwächer oder teilweise gar negativ. Die Grafiken zeigen auch, dass die Entwicklung in einzelnen Berufen von vielen Faktoren abhängt: Die Arbeitslosigkeit entwickelte sich in einigen Berufen bereits vor 2022 merklich anders als in den wenig exponierten Berufen - Divergenzen, die sich im Schnitt aufheben, wenn man alle KI-exponierten Berufe aggregiert. Trotzdem zeigt dies, dass neben generativer KI auch weitere Faktoren zum Anstieg seit 2022 beigetragen haben könnten.
Anmerkung: Die Abbildung zeigt die Entwicklung der Zahl der Stellensuchenden in den 30 Berufen mit höchster KI-Betroffenheit im Vergleich zu Berufen mit wenig LLM-Betroffenheit (unterstes Betroffenheits-Terzil). Wir fokussieren auf ISCO 4-Steller-Berufe mit mehr als 30 Stellensuchenden im Jahr vor der Einführung der LLMs. Die vertikale Linie markiert September 2022 (Einführung grosser Sprachmodelle). Quelle: SECO, Eloundou et al. (2024), eigene Berechnungen.
Ergänzung und Ersetzung von Tätigkeiten durch KI
KI kann Tätigkeiten entweder ergänzen (Komplementarität) oder ersetzen (Substitution). Diese beiden Einsatzformen können sehr unterschiedliche Implikationen für die Arbeitsnachfrage haben (vgl. Brynjolfsson, 2022). Um zu untersuchen, wie sich Beschäftigungsmuster in Abhängigkeit von der Art der KI-Nutzung unterscheiden, verwenden wir Daten aus dem Anthropic Economic Index (Handa et al., 2025). Der Index gruppiert LLM-Chats zu Tasks, ordnet diese den Berufen zu und klassifiziert die Tasks in fünf Gruppen. Siehe Tabelle 1 für die Klassifizierung und Beispiele. Der wichtigste Vorteil dieses Masses besteht darin, dass es im Gegensatz zum Mass von Eloundou et al. (2024) die tatsächliche Nutzung von Sprachmodellen für Aufgaben im Arbeitsprozess abbildet.
Die Analyse legt nahe, dass Berufe, in denen eine höhere Gesamtanzahl an Tasks ausgeübt wird, für die LLMs genutzt werden, ab Herbst 2022 einen signifikant stärkeren Anstieg der Arbeitslosigkeit verzeichneten als Berufe mit einer geringen Anzahl solcher Aufgaben. Die geschätzte Divergenz in der Arbeitslosigkeitsentwicklung beträgt in der letzten Jahresperiode 16,8%. Auch Berufe mit einer mittleren Anzahl an LLM-Aufgaben verzeichneten einen stärkeren Anstieg der Stellensuchenden als Berufe mit einer geringen Anzahl. Da diese Schätzungen auf einem alternativen KI-Betroffenheitsmaß basieren, erhärten sie gleichzeitig den Befund, dass generative KI-Modelle zu einem relativen Anstieg der Arbeitslosigkeit beigetragen haben dürften.
Interessanterweise trugen LLMs in allen Kategorien, die Handa et al., (2025) unterscheiden, zu einem relativen Anstieg der registrierten Stellensuchenden bei. Am stärksten ist der geschätzte Effekt von LLMs bei Prüf- und Verbesserungsaufgaben (z.B. "Ich habe diese SQL-Abfrage geschrieben, um doppelte Kundendatensätze zu finden. Ist die Logik korrekt, und gibt es Verbesserungsvorschläge?") und bei kollaborativen Verfeinerungsprozessen (z.B. „Lass uns eine Marketingstrategie für unser neues Produkt entwerfen. … Guter Start, aber können wir konkrete Metriken ergänzen?“). In den technischen Details wiederholen wir dieselbe Analyse mit den Stellenausstiegsdaten. Diese Analyse bestätigt die Ergebnisse auf Basis der Arbeitslosendaten.
Die Ergebnisse deuten darauf hin, dass sich die Auswirkungen von KI auf dem Schweizer Arbeitsmarkt nicht nur auf rein automatisierende Aufgaben beschränken, die von Sprachmodellen direkt erledigt werden können. Auch Berufe, die das Potenzial haben, durch generative KI und eine verbesserte Mensch-Maschine-Interaktion produktiver zu werden, verzeichnen seit Herbst 2022 einen Anstieg der Arbeitslosigkeit. Die Resultate sprechen für sich genommen dagegen, dass die Komplementaritäts- bzw. Augmentation-Effekte von LLMs genügend gross sind, um die Substitutionseffekte der Technologie auf Berufsebene zu kompensieren. Allerdings sollte dieses Resultat vorsichtig interpretiert werden, da Augmentation-Effekte in Berufen anfallen könnten, welche das Mass von Handa et al., (2025) nicht erfasst. Augmentation-Effekte könnten zudem auch verzögert oder verstreut über viele Berufe hinweg auftreten. Z.B könnte der Sekretär dank LLMs kleinere Marketing-Aufgaben selbst erledigen, die zuvor an eine spezialisierte Agentur mit Markteingfachkräften übergeben wurden. Zudem ist es sehr plausibel, dass Augmentation zu einer Veränderung der Tätigkeitsprofile innerhalb von Berufen führt. Dieser Effekt kann mit Daten auf Berufsebene nicht abgebildet werden.
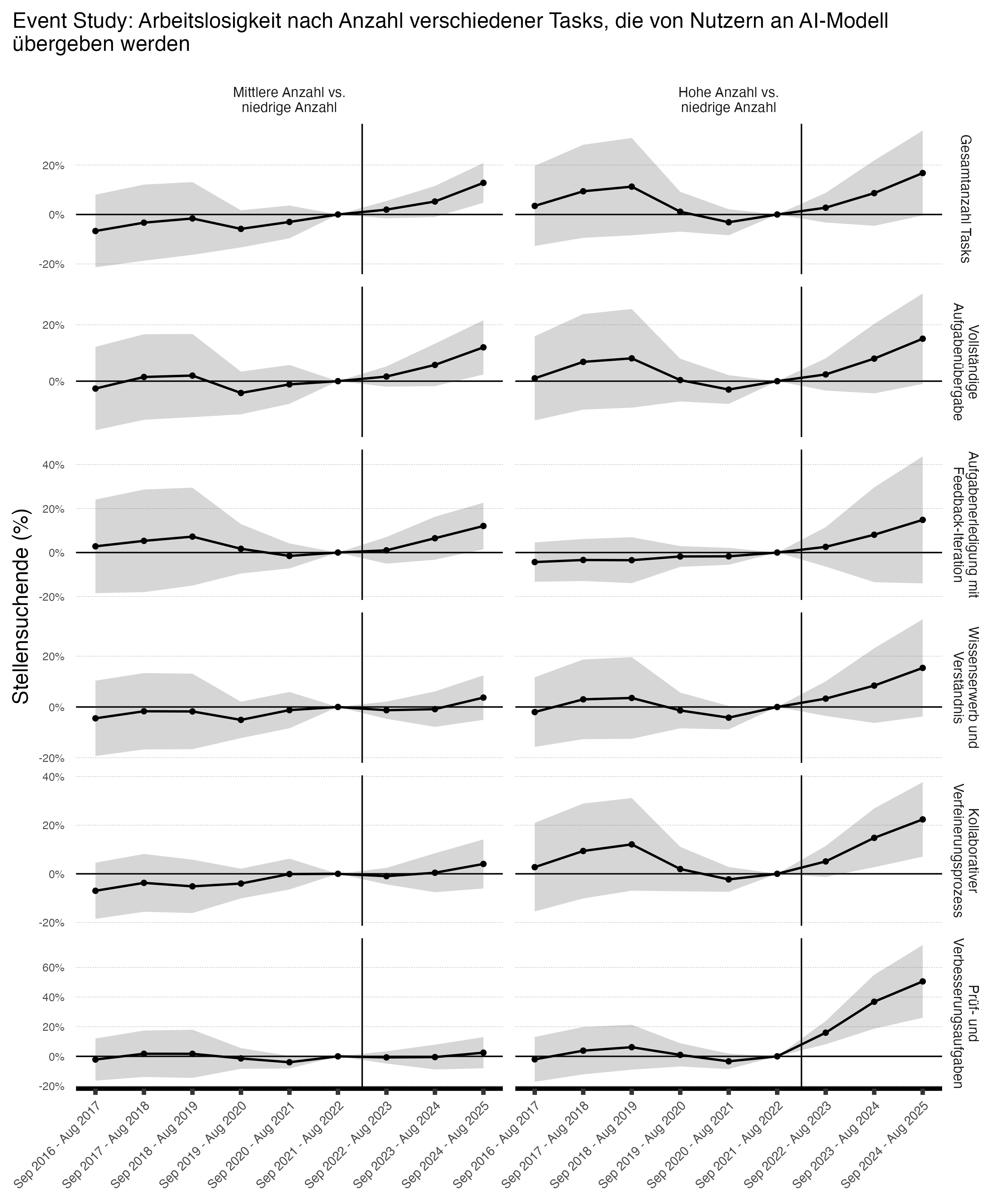
Anmerkung: Ergebnisse einer Poisson-Event-Study-Regression mit 95%-Konfidenzintervallen. Berufe werden nach der Anzahl Tasks pro Kategorie in Terzile eingeteilt, wobei das erste Terzil (niedrigster Wert) als Referenz dient. Marginale Effekte werden als Prozentdifferenzen zur Referenzgruppe angegeben. Die Referenzperiode (Sep 2021 - Aug 2022) ist auf null normalisiert. Die vertikale Linie markiert den Zeitpunkt kurz vor der Einführung von ChatGPT im November 2022. Clustering der Standardfehler auf ISCO 4-Steller Ebene. Interpretation: Positive Werte zeigen eine stärkere Zunahme der Stellensuchendenzahl in Berufen mit höherer KI-Betroffenheit in den verschiedenen Dimensionen relativ zu Berufen mit niedriger Betroffenheit.
|
Ersetzungspotenzial Automatisierende Verhaltensweisen; KI führt Aufgaben direkt mit minimaler menschlicher Beteiligung aus |
Ergänzungspotenzial Augmentierende Verhaltensweisen; KI erweitert menschliche Fähigkeiten durch Zusammenarbeit |
|---|---|
|
Vollständige Aufgabenübergabe Beispiel: „Formatiere diese technische Dokumentation in Markdown.“ |
Kollaborativer Verfeinerungsprozess Beispiel: „Lass uns eine Marketingstrategie für unser neues Produkt entwerfen. … Guter Start, aber können wir konkrete Metriken ergänzen?“ |
|
Aufgabenerledigung mit Feedback-Iteration Beispiel: „Hier ist mein Python-Skript für die Datenanalyse – es ergibt einen |
Wissenserwerb und Verständnis Beispiel: „Kannst du erklären, wie neuronale Netze funktionieren?“ |
|
Prüf- und Verbesserungsaufgaben Beispiel: „Ich habe diese SQL-Abfrage geschrieben, um doppelte Kundendatensätze zu finden. Ist die Logik korrekt, und gibt es Verbesserungsvorschläge?“ |
SCHLUSSBEMERKUNGEN
Unsere Analysen zeigen anhand zweier verschiedener KI-Betroffenheitsmasse und in zwei unabhängigen Datenquellen, welche praktisch den gesamten Schweizer Arbeitsmarkt abdecken, Evidenz dass die Arbeitsnachfrage in KI-exponierten Berufen seit Herbst 2022 zurückgegangen ist. Die Tatsache, dass sich die Arbeitslosigkeit in den wenig und stark exponierten Berufsgruppen vor der Einführung generativer KI-Modelle über einen Zeitraum von mehr als zehn Jahren ähnlich entwickelte und sich dieses Muster gegen Ende 2022 veränderte, weist relativ stark auf einen Zusammenhang mit der Einführung der KI-Modelle hin. Dieser Eindruck verstärkt sich, wenn man die stark betroffenen Berufe im Detail betrachtet. In vielen dieser Berufe ist der zunehmende Einsatz grosser Sprachmodelle im Arbeitsprozess die wohl wichtigste Änderung seit Herbst 2022. Ein gutes Beispiel ist der Beruf der Softwareentwickler*innen, der zuvor jahrzehntelang von geringer Arbeitslosigkeit geprägt war. Dennoch sind die Analysen kein abschliessender Beweis für den Einfluss von KI; alle Faktoren, die ab Herbst 2022 zu einer relativen Verschlechterung der Arbeitsmarktlage in stark gegenüber wenig exponierten Berufen beigetragen haben, könnten die divergenten Arbeitsmarkttrends in den Berufsgruppen (mit)erklären.
Die Ergebnisse werfen zudem die berechtigte Frage auf: Ist es plausibel, dass generative KI-Sprachmodelle bereits in den ersten drei Jahren nach ihrer Einführung derart sichtbare Spuren auf dem Arbeitsmarkt hinterlassen haben? Bei früheren Technologiewellen – etwa bei der Einführung der ersten Bürocomputer oder Industrieroboter – dauerte es Jahre bis Jahrzehnte, bis sich Effekte auf dem Arbeitsmarkt zeigten, etwa in Bezug auf Arbeitslosigkeit und Berufsstruktur. Ein möglicher Unterschied hierbei ist allerdings, dass die Diffusion der KI-Sprachmodelle durch die Anbieter und ihre Adaption im Arbeitsprozess durch die Unternehmen in diesem Fall sehr schnell vonstattenging. So hatte ChatGPT innerhalb weniger Monate Milliarden Nutzende weltweit. Die Technologie war zudem sehr einfach zu adaptieren. Sie ist kostengünstig, ihr probeweiser Einsatz ist mit wenigen betriebswirtschaftlichen Risiken verbunden und erfordert geringe technische Zusatzinvestitionen auf Unternehmensseite. Zudem konnten die meisten Mitarbeitenden die Modelle direkt und ohne grössere Zusatzausbildung einsetzen, da die Modelle in Form von Chatbots in Computerprogramme integriert sind, die bereits umfassend im Arbeitsprozess genutzt werden. Im Gegensatz dazu ist die Einführung eines neuen Softwaretools oder die Anschaffung eines Industrieroboters kostspieliger, komplexer und betriebswirtschaftlich unsicherer. Gleichzeitig können wesentliche Investitionen in (rares) Humankapital sowie Anpassungen im Bereich der eingesetzten Maschinen, Bauten und Technologien erforderlich sein. Deshalb erscheint es uns plausibel, dass die Geschwindigkeit ihrer Verbreitung der grösste Unterschied von KI im Vergleich mit anderen Technologien hinsichtlich ihrer Auswirkungen auf den Arbeitsmarkt ist. Die Geschwindigkeit macht Verwerfungen auf dem Arbeitsmarkt wahrscheinlicher, da den betroffenen Arbeitnehmenden die Zeit fehlt, sich an die veränderte Arbeitsnachfrage anzupassen.
Die Analysen dieses Berichts werfen zudem verschiedene wirtschafts- und arbeitsmarktpolitische Fragen auf. Werden die Ergebnisse dieser ersten Analyse durch künftige Analysen mit Daten zur Beschäftigung oder Löhnen bestätigt? Sind die Effekte vor allem in Unternehmen sichtbar, die Sprachmodelle effektiv im Arbeitsprozess einsetzen? Wie gross ist die Zahl neu geschaffener Stellen durch KI-Sprachmodelle? Welchen gesamtwirtschaftlichen Beschäftigungseffekt haben LLMs? Wie reagieren die betroffenen Arbeitskräfte auf das erhöhte Arbeitslosigkeitsrisiko? Finden sie Stellen in anderen Bereichen des Arbeitsmarkts und falls ja, in welchen? Sind die beobachteten Anstiege in der Arbeitslosigkeit in KI-exponierten Berufen ein persistentes Phänomen (also eine Zunahme der Sockelarbeitslosigkeit in der Schweiz) oder transitorisch, weil sich die betroffenen Arbeitnehmenden künftig entsprechend anpassen (z. B. durch Weiterbildung oder Berufswechsel)? Diese Fragen erfordern vertiefte Analysen, die den Rahmen dieses Berichts sprengen würden.
Technische Details
A. LLM-Expositionsmass nach Eloundou et al. (2024)
Methodik und Konstruktion
Die Grundlage bildet eine standardisierte Liste von Arbeitsaufgaben (Tasks) aus der O*NET-Datenbank. Jeder Beruf umfasst mehrere Aufgaben, die über Crosswalks von O*NET auf ISCO-08 für die Schweiz verknüpft werden. Jede Aufgabe wird einer von vier Expositionskategorien zugeordnet. E0 beschreibt Aufgaben, bei denen ein LLM kaum oder gar keine Zeitersparnis ermöglicht. Kategorie E1 beschreibt Aufgaben, bei denen das LLM allein die Erledigungszeit um mindestens 50 Prozent reduzieren kann. E2 beschreibt Aufgaben, die ohne zusätzliche Tools nicht um 50 Prozent beschleunigt werden, bei denen die Halbierung aber durch die Kombination aus LLM und ergänzender Software erreichbar ist. E3 beschreibt Aufgaben, die Erweiterungen über reine LLM-Fähigkeiten hinaus erfordern, beispielsweise Bildverarbeitung oder robotische Systeme. Die Klassifikation erfolgt sowohl durch menschliche Annotatorinnen und Annotatoren als auch automatisiert durch GPT-4.
Für die Aggregation auf Berufsebene wird das β-Mass als Anteil gewichteter Aufgaben definiert. Formal gilt: β ist gleich der Summe aus der Anzahl der E1-Aufgaben und der halben Summe der E2- und E3-Aufgaben, dividiert durch die Gesamtzahl der Aufgaben eines Berufs. E1-Aufgaben zählen voll, während E2 und E3 mit dem Gewicht 0.5 eingehen, um die zusätzliche Integration und Investition zu berücksichtigen, die über reine LLM-Anwendungen hinausgeht. Die Studie verwendet beide Varianten des β-Masses, basierend auf menschlicher Klassifikation und auf GPT-4-Klassifikation; in der vorliegenden Analyse verwenden wir die GPT-4-basierte β-Variante. Die ursprüngliche Studie validiert die Klassifikationen durch den Abgleich der beiden Quellen. Wir übertragen das β-Mass von O*NET-SOC (2019) über den offiziellen BLS-Crosswalk auf ISCO-08 (CH-ISCO-19), da ISCO für die Schweiz verfügbar ist, SOC hingegen nicht. Für ISCO-Codes mit mehreren SOC-Zuordnungen aggregieren wir mittels US-Beschäftigungsgewichten (OES) zu einem beschäftigungsgewichteten Durchschnitt, der das β-Mass auf ISCO-Ebene liefert (Belot, Kircher und Muller, 2019).
Vorteile und Einschränkungen
Das Mass ist aufgabenbasiert und daher feinschichtiger als grobe Berufsratings. Die Gewichtung von E2 und E3 mit 0.5 reflektiert Heterogenität und Integrationsaufwand. Durch den Einsatz von GPT-4 ist die Klassifikation skalierbar und reproduzierbar, und die Validierung gegenüber menschlichen Einschätzungen erhöht die Glaubwürdigkeit. Grenzen bestehen darin, dass potenzielle Exposition und nicht tatsächliche Nutzung gemessen wird, dass die Klassifikation insbesondere bei E2/E3 fehleranfällig sein kann, dass die Gewichtung eine theoretische Setzung darstellt und dass O*NET-Aufgaben reale Tätigkeiten in der Schweiz nicht vollständig erfassen muss. Zudem impliziert der Ansatz eine gewisse Homogenität innerhalb der Berufe und vernachlässigt innerberufliche Heterogenität.
B. Top-10 und Bottom-10 Berufe: Betroffenheit
Die Top-10-Berufe mit hoher LLM-Betroffenheit umfassen die in der Tabelle aufgeführten Berufsbezeichnungen und β-Werte. Die Bottom-10-Berufe mit niedriger LLM-Betroffenheit sind ebenfalls tabelliert. Diese Auswahl dient als Basis für die deskriptiven Grafiken. Nur Berufe mit mindestens 30 Arbeitslosen zwischen September 2021 und August 2022 werden berücksichtigt.
| Beruf | Betroffenheit | Stellensuchende Okt. 2022 | |
|---|---|---|---|
| Höchste KI-Betroffenheit | Anwendungsprogrammierer/innen | 0.941 | 74 |
| Höchste KI-Betroffenheit | Datenbankentwickler/innen und -administrator/innen | 0.907 | 39 |
| Höchste KI-Betroffenheit | Web- und Multimediaentwickler/innen | 0.876 | 74 |
| Höchste KI-Betroffenheit | Softwareentwickler/innen | 0.868 | 701 |
| Höchste KI-Betroffenheit | Bürokräfte in der Lohnbuchhaltung (m/w/d) | 0.841 | 66 |
| Höchste KI-Betroffenheit | Nicht-akademische Fachkräfte im Rechnungswesen (m/w/d) | 0.783 | 418 |
| Höchste KI-Betroffenheit | Bürokräfte im Rechnungswesen und in der Buchhaltung (m/w/d) | 0.783 | 716 |
| Höchste KI-Betroffenheit | Webmaster (m/w/d) | 0.766 | 34 |
| Höchste KI-Betroffenheit | Autor/innen und verwandte schriftstellerische Berufe | 0.749 | 44 |
| Höchste KI-Betroffenheit | Systemadministrator/innen | 0.700 | 57 |
| ... | |||
| Niedrigste KI-Betroffenheit | Küchenhilfen (m/w/d) | 0.022 | 1'473 |
| Niedrigste KI-Betroffenheit | Hilfsarbeiter/innen im Tiefbau | 0.020 | 97 |
| Niedrigste KI-Betroffenheit | Reinigungspersonal und Hilfskräfte (m/w/d) in Büros, Hotels und anderen Einrichtungen | 0.008 | 3'381 |
| Niedrigste KI-Betroffenheit | Näher/innen, Sticker/innen und verwandte Berufe | 0.004 | 72 |
| Niedrigste KI-Betroffenheit | Athlet/innen und Berufssportler/innen | 0.000 | 67 |
| Niedrigste KI-Betroffenheit | Hauswarte (m/w/d) | 0.000 | 1'179 |
| Niedrigste KI-Betroffenheit | Steinmetz/innen, Steinspalter/innen, -bearbeiter/innen und Steinbildhauer/innen | 0.000 | 37 |
| Niedrigste KI-Betroffenheit | Betonierer/innen, Betonoberflächenfertiger/innen und verwandte Berufe | 0.000 | 335 |
| Niedrigste KI-Betroffenheit | Reinigungspersonal und Hilfskräfte (m/w/d) in Privathaushalten | 0.000 | 473 |
| Niedrigste KI-Betroffenheit | Zubereiter/innen von Fast Food und anderen Imbissen | 0.000 | 211 |
C. Statistische Methoden
C.1 Event-Study-Design
Die Event-Zeit wird in Jahresfenstern relativ zum Ereignis gemessen, mit den Perioden −6 bis −1 vor der Einführung, 0 als Periode der Einführung von ChatGPT (September 2022 bis August 2023) und +1 sowie +2 als die folgenden beiden Jahre. Die Expositionsgruppen werden in Terzile eingeteilt, wobei das erste Terzil die Referenzgruppe mit niedriger LLM-Betroffenheit bildet. Die Referenzperiode ist −1. Das Design erlaubt die Trennung allgemeiner Zeittrends von strukturveränderten Entwicklungen nach dem Ereignis und stützt sich auf die Parallel-Trends-Annahme zwischen Berufen mit niedriger und hoher Betroffenheit, die wir in den Daten visuell und mittels Pre-Trend-Koeffizienten prüfen.
C.2 Regressionsmodelle
Für die Arbeitslosigkeit verwenden wir ein Poisson-Regressionsmodell, mit Interaktionen zwischen Expositionsterzilen und Event-Zeitfenstern. Die Standardfehler werden auf ISCO 4-Steller Ebene geclustert. Das Panel umfasst alle Kombinationen von ISCO, Altersgruppe und Zeitperiode; Zellen ohne Stellensuchende behandeln wir als Nullen, da sowohl die Stellensuchenden- wie auch die Inseratedaten praktisch den gesamten Arbeitsmarkt abdecken. Die Terzilgrenzen werden unter Verwendung der Stellensuchendenzahlen in der Referenzperiode gewichtet bestimmt. Für die Stellenausschreibungen schätzen wir Modell auf Firmen x Terzil-Ebene. Standardfehler werden auf Firmenebene geclustert.
C.3 Marginale Effekte
Die berichteten Effekte sind marginale Effekte, die wir aus den Poisson-Modellen herleiten. Sie sind als Prozentpunktdifferenzen gegenüber der Referenzgruppe skaliert und werden für die grafische Darstellung um den Faktor 100 skaliert. Standardfehler werden mittels Delta-Methode berechnet. Die Konfidenzintervalle betragen 95 Prozent. Die Achsenbeschriftungen in den Abbildungen folgen der oben beschriebenen Event-Zeitdefinition.
D. Datenaufbereitung
D.1 Arbeitslosigkeitsdaten
Die monatlichen Stellensuchendenzahlen des SECO decken den Zeitraum von September 2020 bis August 2025 ab. Für die deskriptiven Analysen verwenden wir die monatlichen Reihen. Für die Event-Studies aggregieren wir in Jahresfenstern von September bis August. Die Altersgruppen lauten ursprünglich 15–19, 20–24, 25–29, 30–34, 35–39, 40–49 und 50+. Für die Event-Studies fassen wir die Altersgruppen zu 20–49 Jahre und 50–65 Jahre zusammen; die Gruppe 15–19 Jahre wird aufgrund geringer Fallzahlen ausgeschlossen.
D.2 Stellenausschreibungsdaten (x28 AG)
x28 sammelt und systematisiert Online-Stellenausschreibungen in der Schweiz durch kontinuierliches Crawling von Unternehmenswebseiten sowie - falls dort keine Stellen ausgeschrieben sind - von Jobbörsen. Duplikate werden automatisch erkannt und eliminiert. Die Anzeigen werden mittels offizieller Branchen- und Berufsklassifikationen (ISCO-08) systematisiert. Die Abdeckung umfasst Online-Stellen, die den Grossteil des Marktes repräsentieren; gemäss Unternehmensumfragen ist die Firmenwebsite der am weitesten verbreitete Kanal für Stellenausschreibungen ist. Der Datenzugang erfolgt wöchentlich über eine API. Der tägliche Stock berechnet sich als kumulierte Summe neu aufgeschalteter Anzeigen abzüglich am selben Tag entfernter Anzeigen und misst die Anzahl aktiver Stellenausschreibungen. Für monatliche Grafiken verwenden wir den Durchschnitt des täglichen Stocks über alle Tage eines Monats. Für jährliche Event-Studies bilden wir den Durchschnitt der täglichen Bestände innerhalb der jeweiligen September-bis-August-Periode. Für deskriptive Analysen summieren wir über Unternehmen innerhalb von ISCO und Terzil, während wir für Event-Studies ein Panel auf Ebene Unternehmen, Terzil und Jahr konstruieren.
E. KI-Betroffenheitsmass von Handa et al. (2025)
Zusätzlich zum Expositionsmass nach Eloundou et al. (2024) nutzen wir ein ergänzendes Mass aus Handa et al. (2025), das die tatsächliche Nutzung generativer KI auf Task-Ebene erfasst. Die Autorinnen und Autoren analysieren hierzu mehrere Millionen anonymisierte Interaktionen mit dem Sprachmodell Claude.ai und ordnen jede Anfrage einem spezifischen Task im US-amerikanischen O*NET-System zu. Auf dieser Grundlage lässt sich bestimmen, für wie viele Tasks eines Berufs tatsächlich KI eingesetzt wird.
Handa et al. (2025) identifizieren fünf charakteristische Nutzungsmuster, die beschreiben, wie Menschen KI in ihre Arbeitsprozesse integrieren. Diese Muster sind: vollständige Aufgabenübergabe (die KI übernimmt eine Aufgabe vollständig), Aufgabenerledigung mit Feedback-Iteration (die KI löst Aufgaben schrittweise mit Rückmeldungen), kollaborativer Verfeinerungsprozess (Mensch und KI arbeiten gemeinsam an der Verbesserung von Inhalten), Wissenserwerb und Verständnis (die KI wird zur Erklärung und zum Lernen eingesetzt) sowie Prüf- und Verbesserungsaufgaben (die KI überprüft und optimiert bestehende Arbeitsergebnisse). Tabelle 1 zeigt diese fünf Typen mit Beispielen aus den analysierten KI-Interaktionen.
Analog zum Vorgehen bei Eloundou et al. (2024) übertragen wir diese Task- und Berufszuordnungen über den offiziellen Crosswalk von O*NET-SOC auf ISCO-08 (CH-ISCO-19), um das Mass für den Schweizer Kontext nutzbar zu machen. Dabei verwenden wir die Gesamtzahl der Tasks pro Beruf, bei denen eine KI-Nutzung beobachtet wird, als Indikator für die intensive Einbindung von KI in berufliche Tätigkeiten. Dieses Mass ergänzt unser β-Mass, das die potenzielle Exponiertheit gegenüber KI abbildet, um eine Dimension der tatsächlichen Nutzung.
Die Interpretation dieses Indikators erfordert allerdings Vorsicht: Die zugrunde liegenden Daten beziehen sich auf Interaktionen mit einer einzelnen KI-Plattform und erfassen beispielsweise nicht, wie ChatGPT oder Gemini eingesetzt werden. Zudem kann die Zuordnung von US-amerikanischen SOC-Codes zu Schweizer ISCO-Codes mit Unsicherheiten behaftet sein. Dennoch bietet das Mass wertvolle zusätzliche Evidenz zur Verbreitung von KI im Arbeitsalltag und erlaubt eine differenziertere Einschätzung, welche Tätigkeitsbereiche bereits heute durch generative KI-Systeme unterstützt oder automatisiert werden.
Zusatzabbildungen
Zusatzabbildung: Parallele Trends über einen längeren Zeitraum
Die folgende Abbildung zeigt die geschätzten Differenzen in der Arbeitslosigkeit zwischen den Expositionsgruppen für den erweiterten Zeitraum bis 2010. Die Ergebnisse bestätigen, dass die Unterschiede zwischen den Terzilen vor September 2022 statistisch nicht signifikant von null abweichen, was die Annahme paralleler Trends stützt.
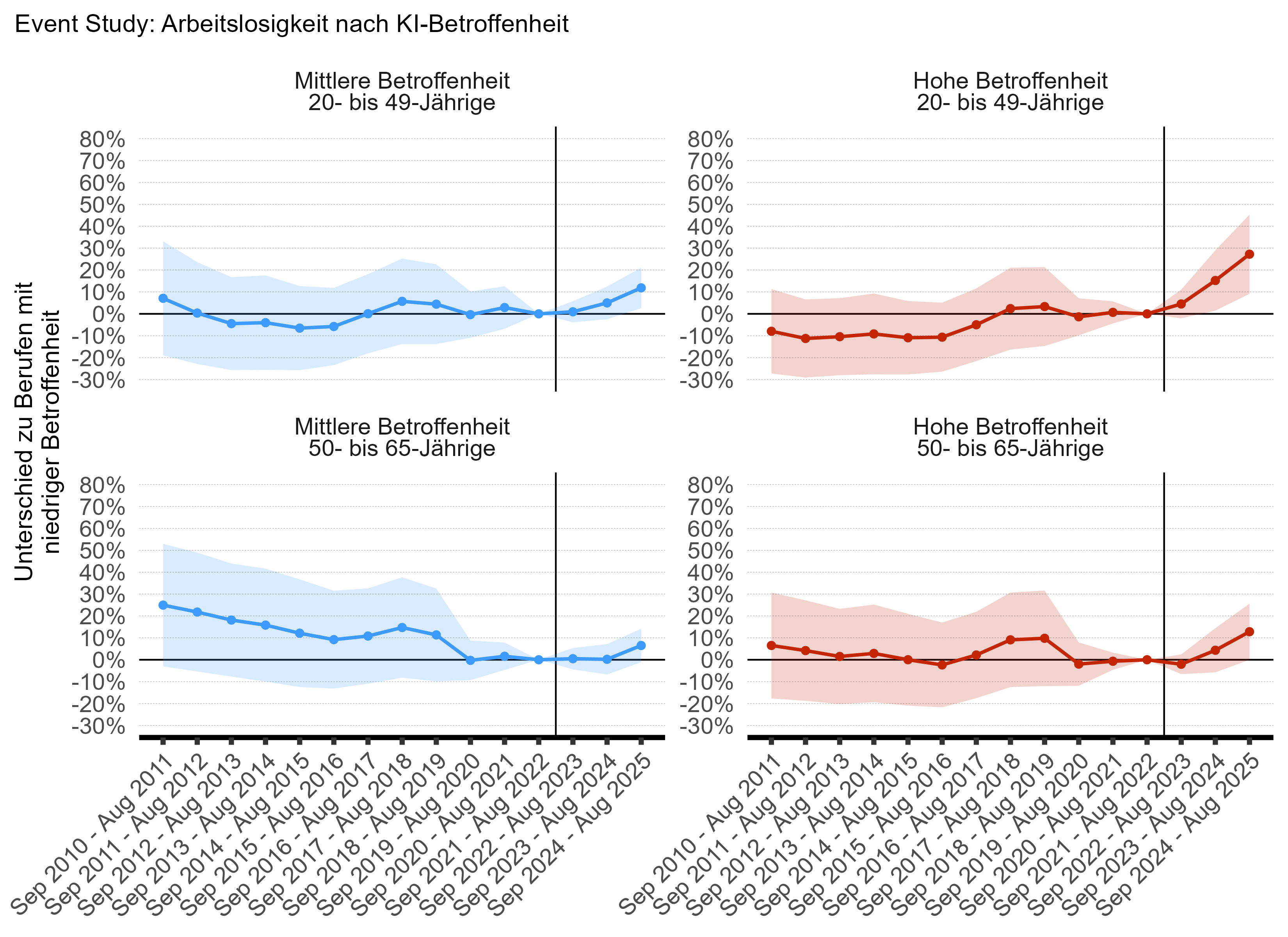
Anmerkung: Erweiterte Event-Study mit Beobachtungen ab 2010. Quelle: SECO, eigene Berechnungen.
Zusatzabbildung: Ergänzung und Ersetzung von Tasks bei den Stellenausschreibungen
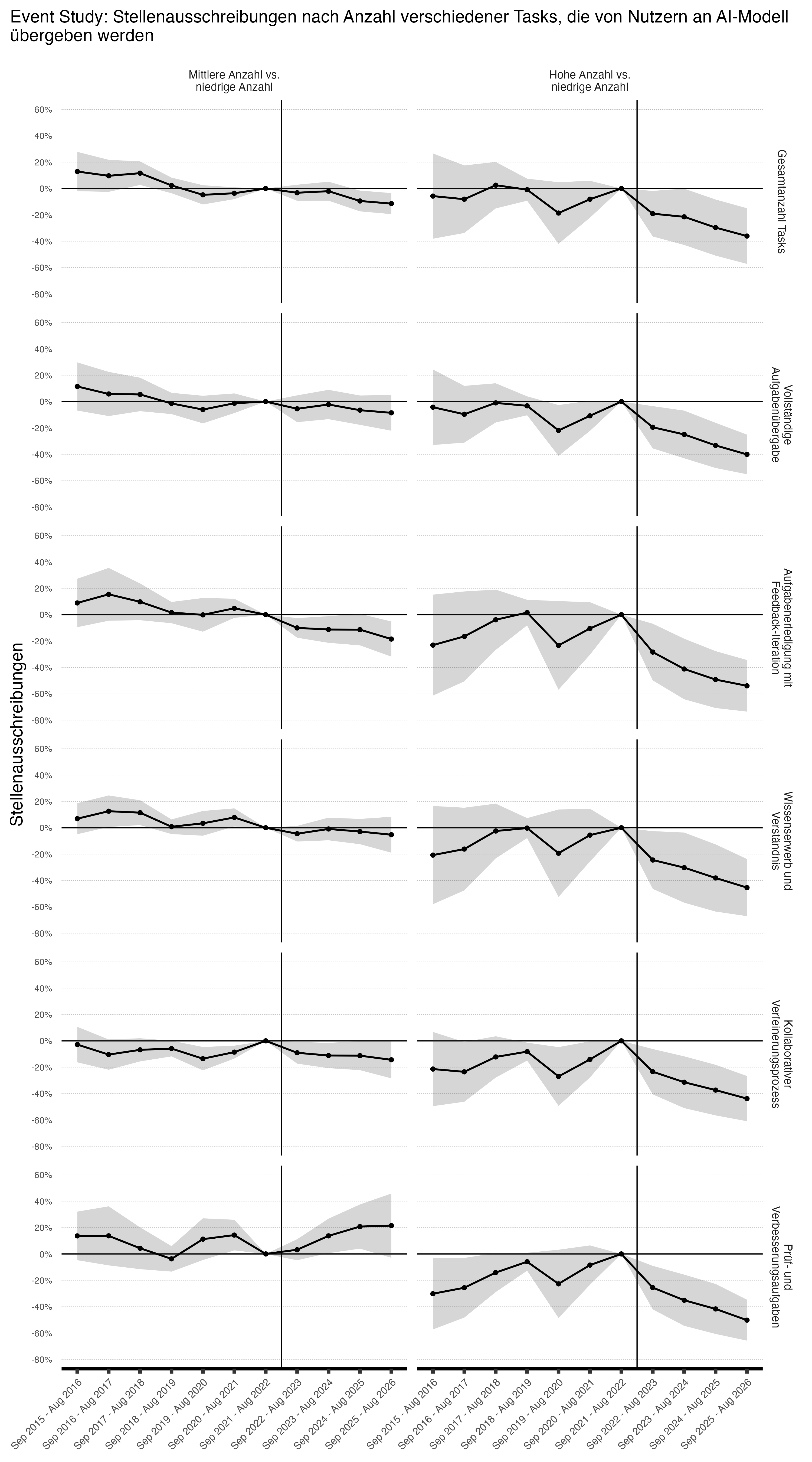
Anmerkung: Ergebnisse einer Poisson-Event-Study-Regression mit 95%-Konfidenzintervallen. Berufe werden nach der Anzahl Tasks pro Kategorie in Terzile eingeteilt, wobei das erste Terzil (niedrigster Wert) als Referenz dient. Marginale Effekte werden als Prozentdifferenzen zur Referenzgruppe angegeben. Die Referenzperiode (Sep 2021 - Aug 2022) ist auf null normalisiert. Die vertikale Linie markiert den Zeitpunkt kurz vor der Einführung von ChatGPT im November 2022. Clustering der Standardfehler auf ISCO 4-Steller Ebene. Interpretation: Negative Werte zeigen eine stärkere Abnahme der Zahl an Stelleninseraten in Berufen mit höherer KI-Betroffenheit in den verschiedenen Dimensionen relativ zu Berufen mit niedriger Betroffenheit.
Literatur
Belot, Michèle, Philipp Kircher und Paul Muller (2019). „Providing advice to jobseekers at low cost: An experimental study on online advice“. The Review of Economic Studies, 86(4), 1411–1447.
Brynjolfsson, Erik, Bharat Chandar und Ruyu Chen (2025). „Canaries in the coal mine? Six facts about the recent employment effects of artificial intelligence“. Stanford Digital Economy Lab, August 2025.
Eloundou, Tyna, Sam Manning, Pamela Mishkin und Daniel Rock (2024). „GPTs are GPTs: An early look at the labor market impact potential of large language models“. Science, 381(6659).
Handa, Ryo, Jack Clark, Jared Kaplan und Dario Amodei (2025). „The Anthropic Economic Index: Measuring Generative AI Use across Occupations“. Anthropic Research Paper Series, Nr. 5.
Bericht erstellt: 25/10/2025
Kontakt: klaeui@kof.ethz.ch